How to Use Machine Learning to Find Podcast Topics

I have always been interested in automating mundane tasks. I’m one of those people who would rather write a script for half a day to automate some manual tasks that would only take me 30 minutes. I can’t help it. It’s the engineer in me. I did the same kinda thing when I created the Podcast Market Fit survey.
Another topic I have always been interested in is how computers can learn to do said mundane tasks. Early in my career, I worked at a semiconductor company that built neural network chips to solve problems like image compression, character recognition, face recognition, etc. That company is long gone (it folded back in 1999) but the types of tasks our chips could do you can now do cheaply on the web. That’s what got me thinking about a nagging problem I have related to my podcast, The Entrepreneur Ethos, how to come up with podcast topics?
Podcast Topics Are Hard to Figure Out
I’m sure it might seem obvious what a podcast about my book, The Entrepreneur Ethos, should be about but it’s actually hard to figure out what topics to cover. Sure, there are standard topics like the traits, values, beliefs, skills, life journey, mindset, etc. but who knows if anyone wants to listen to that.
So I decided to try and figure out what podcast topics I should cover on the podcast by doing an analysis of the first 30 guests. I did this for three reasons:
- They are all entrepreneurs and my target demographic
- I wanted an easy way to repurpose the interviews into smaller ones based on what topics people might be interested in.
- I want to improve my site’s SEO to get more listeners.
The good news is that I do have a rough idea of podcast topics that are interesting but I did not want to listen to all the episodes again. I did look at the show notes but those are incomplete and based on my faulty memory.
Ideally, I wanted an automated way to look at all 30 to see the trends in keywords along with where in the episode those keywords were talked about. That’s why I dusted off my python skills and jumped into the deep end of Machine Learning.
Going Down the Machine Learning Rabbit Hole
A lot has changed in Machine Learning (ML) since 1999. In fact, there are so many different types of platforms and services that I had to enlist my friend Troy to educate me.
Troy launched Productive AI (along with a podcast) to help people like me figure out how to make AI (and Machine Learning) into a productive tool. His post on a simplified view of the AL/ML stack is a must-read on this and helped me figure out the what and how the heck I could do this.
With Troy’s help, I settled on using Amazon Web Services Transcribe and Monkey Learn Text Extractor to extract keywords for individual episodes as well as all episodes combined. I’ll go into the details more below.
Manual Methods vs Machine Learning to Help Find Podcast Topics
My guess is if you got this far you’re either 1) an engineer of some sort or 2) a podcaster that wants to figure out how to create SEO rich episodes to get discovered. If you’re neither, then I clearly did not nail the SEO or demographic for this post -- thus the reason I need help ;-).
My First Pass: Manually Scanning Show Notes
Since I upload all of my episodes into Simplecast, which is what Bluewire Podcasting uses since I’m an advisor there, I did a quick scan of the show notes every time to select keywords. So I know a little bit about the keywords for each show but it’s hard to keep track of all of them (you’ll see how many I found later on).
It’s also hard to figure out if there are any common keywords among episodes or guests. The only one that easy to figure out is my guests from Founders Network. I happen to be the San Francisco Regional Chair this year (2020) and wanted to interview all 194 SF chapter members. That at least gives me one keyword that should show up in my analysis -- founders network.
Other than that, it’s going to be pretty hard to sift through all 30 interviews to find some trends. I also want transcripts and keyword analysis on all my episodes moving forward so I can update and refine the questions I ask.
I also want to find a particular podcast topic that listeners want to know about, so I can then ask those questions to my guests as well.
My Second Pass: Transcripts using Machine Learning
I figured that the best way to do this keyword analysis was to transcribe the episodes ( Speech to Text) and then search for words. Luckily, that’s pretty easy using Amazon Transcribe (hat tip to Troy again for that).
It’s pretty straight forward to run and all you need is a .mp3 file of your episode, which is easily downloaded via your podcast feed (more on that later).
The only problem is that the results come via a JSON file that is cumbersome to look at, which means writing (or finding) code that can translate it into something reasonable, like a .docx or a spreadsheet. Can you see how this is getting more and more complex and manual in nature? Can you see what’s coming from my “I must automate this manual process that’s driving me crazy” mind?
My Third Pass: Where do People Listen to my Podcast?
I took a look at where people have been listening to my podcast and it turns out that about ⅓ listen directly on my site (Simplecast is the embed for each episode):
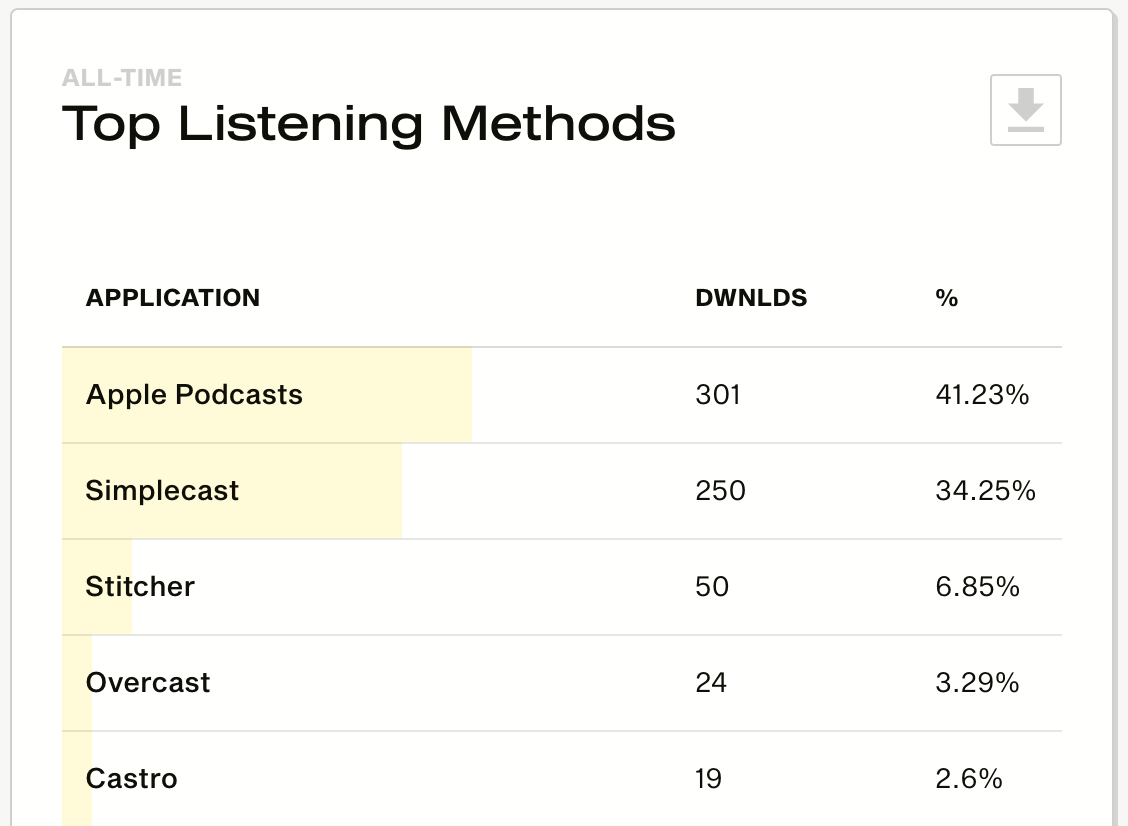
This is encouraging since an SEO strategy will help me with being found by listeners even more. I also took a quick look at other Blue Wire Pods and for most, their Simplecast listens are well below 5%. Clearly, there is an opportunity to improve my results and also Blue Wire Podcasts.
Podcast Topic Analysis Pipeline
I’m not going to bore you with the countless hours of manual cut, paste, click, download, scan, find, replace, or save as I did to get to this point. Let’s just say that it’s more hours than I care to admit to. Although it did give me a new appreciation for how difficult it is to actually use Machine Learning that will give back useful information.
So I decided to automate the process to save my sanity and to experiment with the ML API’s out there from Amazon and Monkey Learn (Fun Fact. I was at 500 startups Batch 14 with the guys from Monkey Learn. Great to see them still around.)
Feel free to skip this whole section if you just want the results. It’s going to get geeky!
Step 1: Download the Podcast Episode Audio Files
I needed a way to download the audio files for the analysis. Thankfully, every podcast has an RSS feed that provides all the information. I wrote a python script that would scan the RSS feed and download each .mp3 file for analysis. I found my feed on Simplecast and then used a feed parser to get all the details:
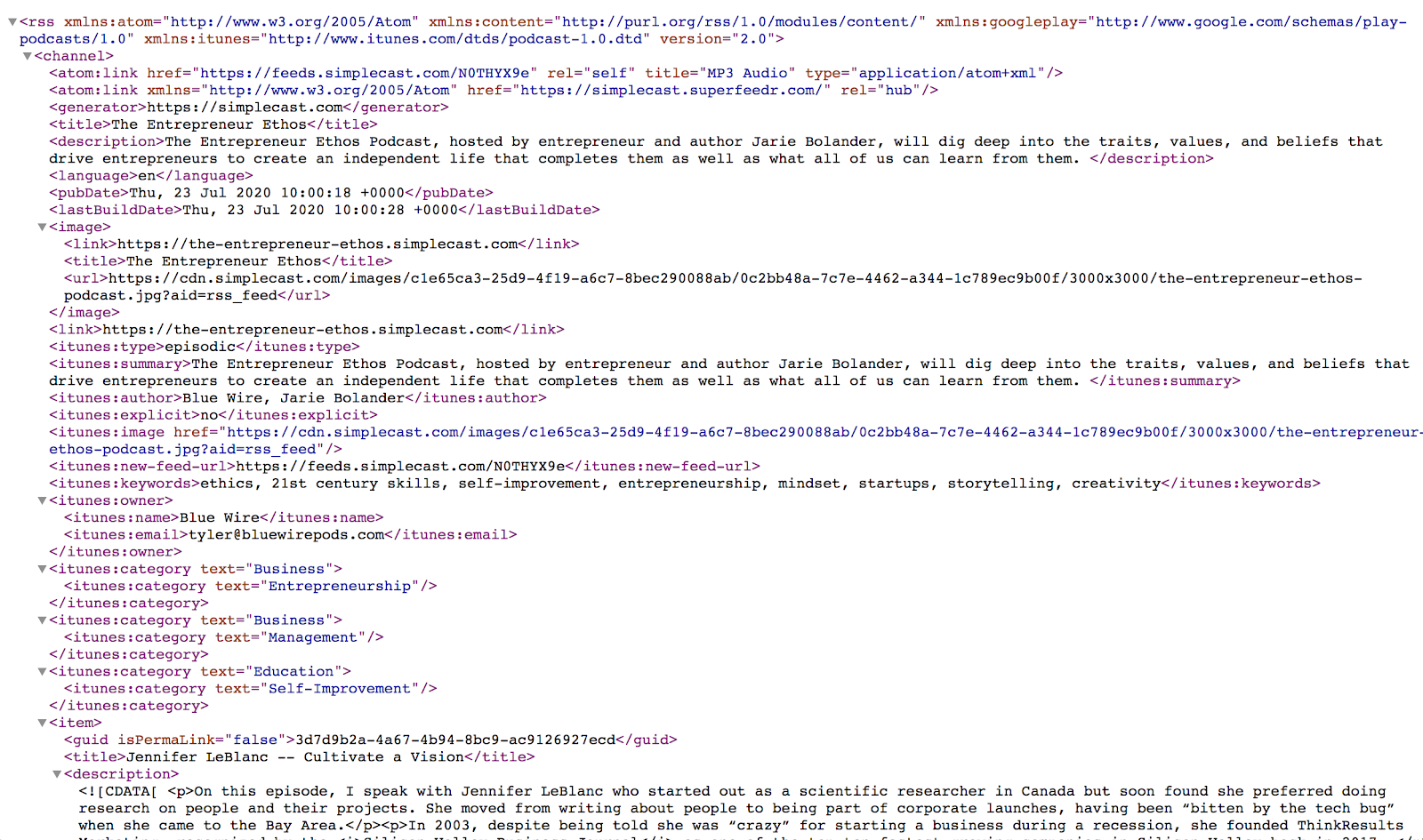
Each time I run the script, it scans the feed and downloads the latest episodes I don’t have to a Ubuntu instance on my Digital Ocean account. The script then launches the Amazon Transcribe job.
Step 2: Transcribe Audio with Amazon Transcribe
In order to use Amazon Transcribe, you have to upload your files to S3. So the script uploads the audio files to S3. After that, the script uses the python library boto3 to launch the job with the option to identify the number of speakers in the stream. For me, that’s always going to be 2 speakers, which is important for the formatting step next.
Step 3: Format Amazon Transcribe Output
The output of the Transcribe job is a JSON file with all sorts of info in it. It’s actually hard to even read (see below):
Luckily, I found a python library called tscribe, which takes the above and creates this:

The .csv file will have two purposes. The first is to find the time that keywords occur and the second is the text to feed into the next stage.
Step 4: Use Monkey Learn for Keyword Analysis
Each transcript is fed into Monkey Learn’s Keyword Analysis API. What’s nice about Monkey Learn is that you can test out any text on their dashboard to see if it will give you what you want. See below for their simple example:
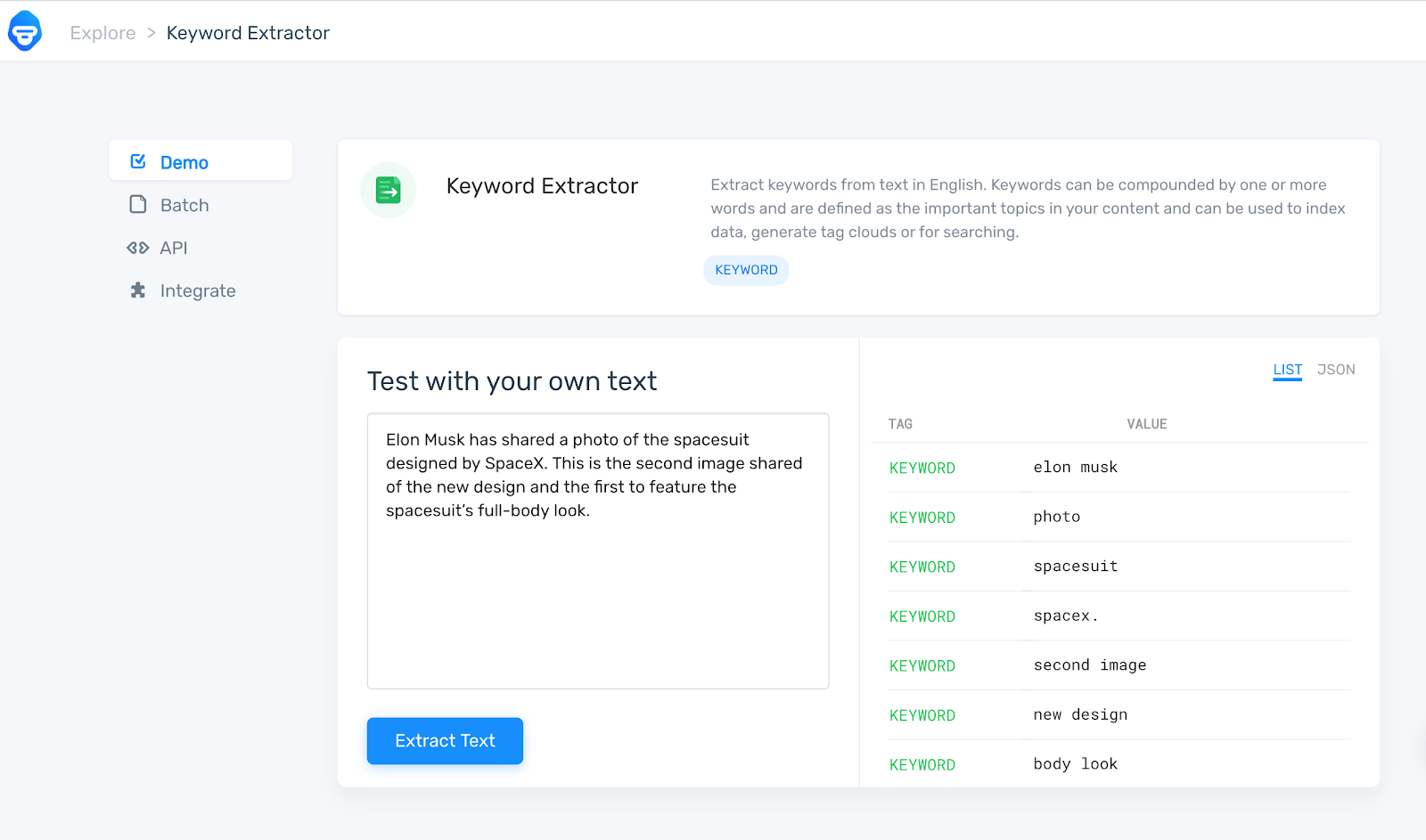
Once I have all the keywords from each episode, I combined them all into one big text file to build a word cloud and look for SEO keyword opportunities. For the 30 episodes I looked at, there were 841 total keywords of which 328 were unique. I took the list of 841 words and made a word cloud.
Step 5: Build a Word Cloud using Monkey Learn
Monkey Learn has a free word cloud tool that pretty darn slick. It’s simple to use and has a bunch of parameters you can play with. I choose to display the top 20 words that it found. See below:
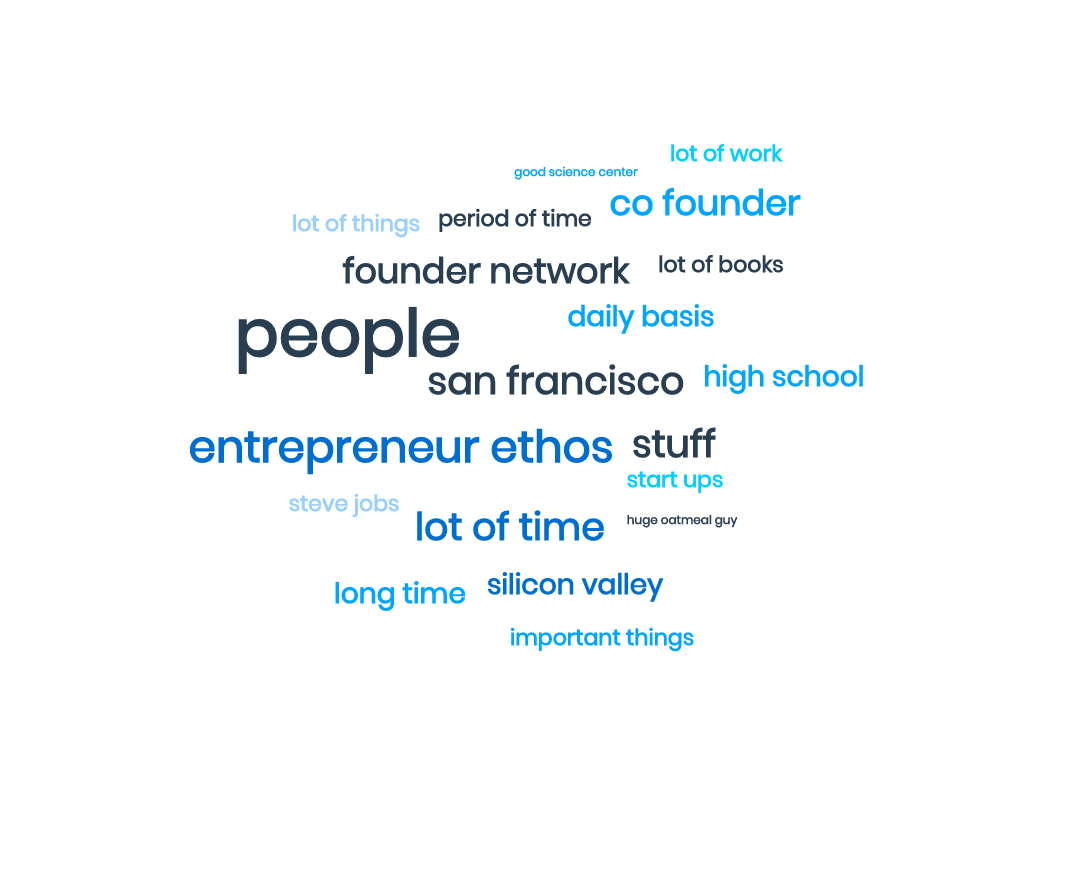
We’ll look at what this means later in the analysis part but what’s nice is that a quick glance shows Entrepreneur Ethos showing up. Yippee! I’m on to something.
The next step is to figure out which one of these keywords (actually all 328 unique words) people are interested in. For that, I used one of my favorite SEO tools, Ahrefs.
Step 6: Use Ahrefs to See Which Podcast Topics to Focus on
Ahrefs is a wonderful tool to hunt for keywords, among other things. Taking all the unique keywords from above and putting it into the Keyword Explorer gave me this.
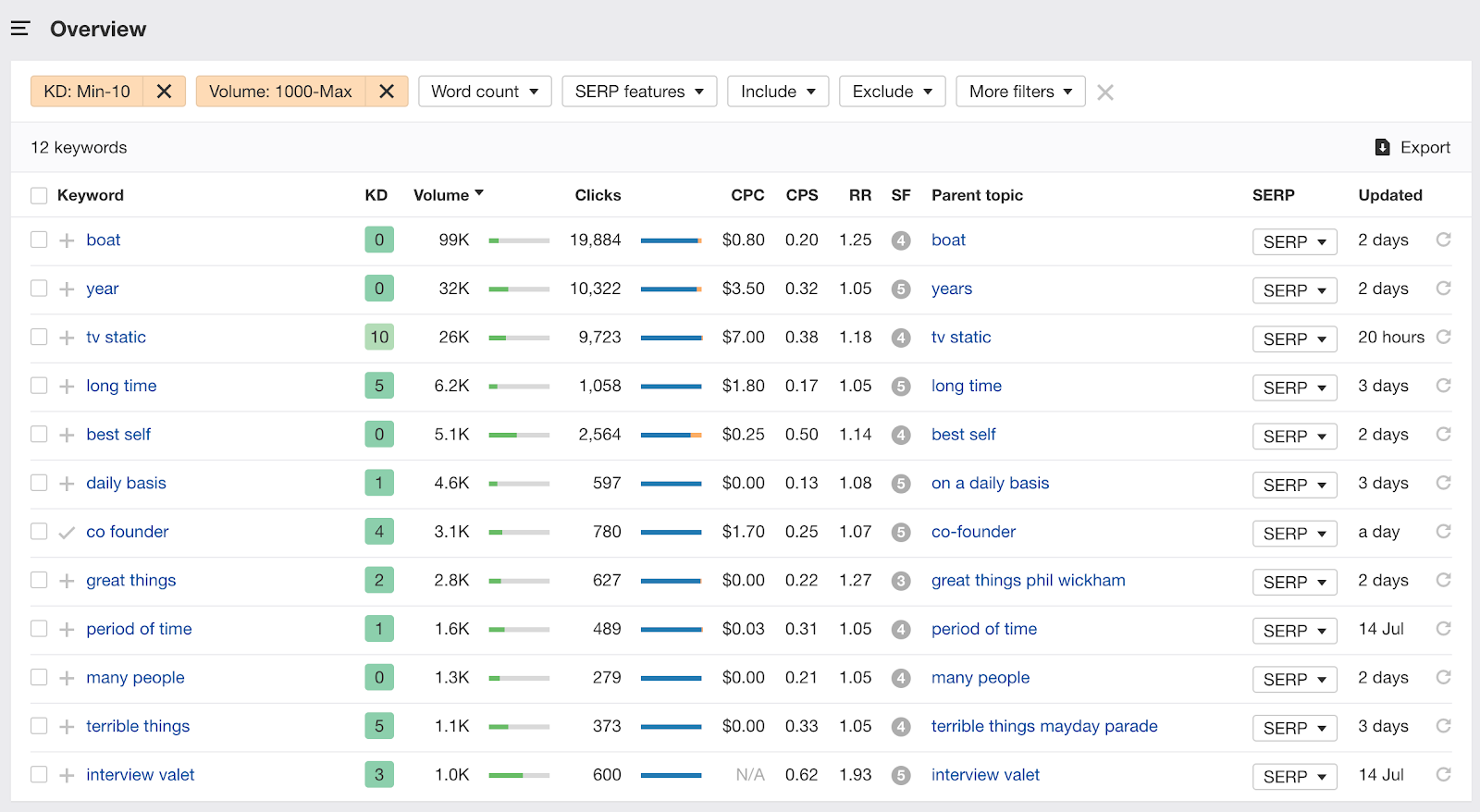
With all this data, I now have what I need to figure out what podcast topics to talk about, who has talked about them and keywords to start building better SEO for my site.
Podcast Topic Analysis Results
Okay. So now I have tons of data to look at and it only took me like a week or so to get here. Whew. Here is what I learned from all this:
#1 Cofounder is a Popular Keyword + SEO Rich
A lot of my guests talk about their cofounders. In particular, how to find one, get along with one, and techniques for conflict resolution. It also turns out that people search for the keyword cofounder to find out similar things. This a great insight in that my guests have a lot of great things to say about the cofounder topic and people are interested.
#2 Founders Network Shows Up as Expected
Out of the 30 interviews I did, 12 were from Founders Network. I would except that the keyword extractor would pick up on that, which it did. I think that’s good confirmation that the extractor is working as expected. I’ll continue to look for unique keywords like that to further test, refine, and validate the machine learning model.
#3 Some Guests Are Good At Keywords
When I took a look at the individual episode keyword lists, I found some rather interesting results. It turns out that some guests are really good at creating keywords that relate to what they do. In particular, Tom Schwab from Interview Valet had a lot of unique keywords to what he does.
Those keywords include remote team, nuclear power plant, work-life balance, chief evangelist officer, Interview Valet, podcast interview, and podcast relationship manager. Way to go Tom!
One of his words, in particular, Interview Valet, also shows up in the Ahrefs as a Keyword Difficulty (KD) of less than 10 and a Volume of 1k and above, which is a good criterion for keyword research.
I’m going to do some more research into the other guests to see how to repurpose the past interviews to improve discovery and podcast topic refinement. That I think will be a rick vein to mine.
#4 Need to Refine the Model
I do have some work to do on the model and text formatting. A lot of the keywords that show up are not helpful. Like a lot of things, a lot of work, a lot of books, etc. For that, I’m going to explore how to exclude certain words when I send the text off to the extractor.
I’m also going to run new episodes and add those to the data set to see how the trends happen over time. This will be important to see if the new questions I ask and the topics people want to talk about change over time.
What’s Next
I’m going to use all this data to do a couple of things different from the podcast. The first thing is that I’m going to ask my guests about their cofounders and if they have any tips for making the cofounder relationship better.
The second thing is that I’m going to create a bunch of bonus episodes centered around how my past guests have dealt with cofounder issues. This seems to be a good podcast topic to discuss because a lot of my guests talked about it and people search for it as well.
Thanks for taking the journey with me. I hope you’ll subscribe to my podcast and listen to how my interviews evolve because I’ll be using machine learning to find podcast topics to talk about.


{kind=link}